12 Oct 2025
https://tribecap.co/kapital-thriving-in-a-desert/
An analysis on Kapital, the company.
They first started with a dashboarding software as a wedge, then moved into a large platform, offering loans, credit cards, expense management and other financial services.
Main product offerings being, loans, credit and debit cards and invoice management.
Problem: Tackling this issue because SME businesses are underserved by loans.
Insight: They can use the metrics from the dashboarding software to help underwrite its customers successfully. Enabling them to get a low default rate.
Mentions about the idea of cohort expansion. The idea that old cohorts don’t deteriorate but actually increase spend over time.
Previously fintech companies focused on scale metrics, GTV (gross transaction volume) or TPV (total payment volume). Article highlights to focus more on operating efficiently.
Apparently dashboard product has a 100% retention to date. Kinda absurd.
26 Jul 2025
Working at a place that is dominantly online and not in office I’ve come to realise that a large proportion of the value we produce is not in the code you write but in the code you review as well.
If this is true, it makes a lot of sense to invest in the skill of reviewing code as much as I have already invested into the art of coding.
This post aims to tackle as a guide and cook book for performing better code reviews.
What is the purpose of a code review?
A good way of thinking about a code review is as a process of adding value to existing code.
So how can you add value to existing code?
- Make it more simpler
- Make is more correct
- Make it more performant
Another perspective is that the purpose of a code review is to fight against the natural nature of a codebases, they deteriorate in quality over time. Like a ratchet each time you loosen the bar, it stays there, and never goes back. The core principle being:
In general, reviewers should favor approving a CL once it is in a state where it definitely improves the overall code health of the system being worked on, even if the CL isn’t perfect.
The functionality
- Does the code do what the developer intended
- Is what the developer intending necessary
- Are there any edge cases
- Are there any concurrency problems
- Are there any bugs
- Can it cause deadlocks or race conditions
The complexity
- Can it be simpler
- Is it too generic
- Is it solving additional problems
The tests
- Are there tests?
- Are there all the tests for edge cases
- Are the tests simple
The naming
The comments
- Are the comments necessary
- Are there comments explaining why some code exists, not how it works
The observability
- Can I detect that this code fail
- Is there any visibility loss?
The style
- Is it well indented?
- Is it consistent with the codebase?
- Do I want to maintain this?
The broader context
- Is the code improving the code health of the system or is it making the whole system more complex
- Don’t accept code that degrades the code health of the system, THEY ADD UP.
The good things
- What are the good things, you like
In summary
- The code is well-designed.
- The functionality is good for the users of the code.
- Any parallel programming is done safely.
- The code isn’t more complex than it needs to be.
- The developer isn’t implementing things they might need in the future but don’t know they need now.
- Code has appropriate unit tests.
- Tests are well-designed.
- The developer used clear names for everything.
- Comments are clear and useful, and mostly explain why instead of what.
How do you actually do a code review
- Does the intent make sense?
- Look at the most important part of the change.
- Look at the rest of the code.
Does it make sense?
- Does the description make sense
- Is it needed
Look at the core logical impl
- Try to find major design problems first, so you don’t need to review the rest of the impl.
- Major changes take a while so you want to give feedback quickly
Look at the rest
- Review all the files, now with the context of whats happening
On speed
The velocity of the team is dependant on iteration speed, so quick reviews are the life blood of the team. You should do a code review shortly after it comes in!
On pitfalls
- Don’t have multiple round trips, reduce this time as much as possible
- Don’t make it a ransom note, don’t hold the review hostage
- Don’t have two conflicting reviewers fighting with each other
- Don’t have a guessing game. Don’t just criticise the solution and not give a solution. Make it specific. Not a vague hammer to hit them.
- Start with the bombshell, not the nits. The nits come after the major design reworks.
- Never flip slop between your thoughts.
General idea is to do something like this
- What is wrong with the code?
- Why is it wrong?
- How to fix it? Be actionable!
And to place color on
- Is it blocking?
- So they don’t waste time on bikesheds!
Something to consider is labelling comment severity
- Nit: This is minor
- Optional: I think this may be a good idea
- FYI: Could be interesting
Additional principles
- Never say the word you in a code review: never attack the author, say WE!
- Use the passive voice. Only ask questions, What about renaming this variable?
- You aren’t commanding them, you’re suggesting ideas to make this code better.
- Tie your feedback to principles.
And finally on the other side, what should you consider as the author
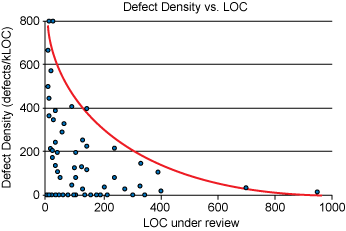
A pretty fun graphic from cisco code reviews shows that at most 400 lines of code, the amount of issues you can notice significantly diminish. So try to split it up!
What makes a code review small?
- It does one thing
- It tests that one thing
- What are the implications of this one thing
So how can you split up a change?
- Stack changes, pull out precursors and incrementally contribute
- Split by files, update each file change independently
- Split horizontally: design your code in such a way that you can easily cut multiple code reviews without them interfering
- Split by intent/ logical change
- Split out refactors
Appendix
https://github.com/google/eng-practices/blob/master/review/index.md
https://www.chiark.greenend.org.uk/~sgtatham/quasiblog/code-review-antipatterns/
https://philbooth.me/blog/the-art-of-good-code-review
https://bitfieldconsulting.com/posts/code-review
https://lindbakk.com/blog/code-reviews-easy-in-theory-difficult-in-practice
https://smartbear.com/learn/code-review/best-practices-for-peer-code-review/
https://mtlynch.io/human-code-reviews-1/#start-reviewing-immediately
https://mtlynch.io/code-review-love/
26 Jul 2025
A common theme i’ve noticed with myself and talking to my peers is that its very easy to get into a rut or a plateau in your life, a comfortable life doing the same things each week. Not that thats bad or anything but many people have an underlying want to break out of this, but are unclear on how or what they even want to break out to.
What do you actually care about?
One way we can tackle this is by listing what your values are and working back from those.
Innately what do you care about and want?
- Is it money?
- Is it fame?
- Is it power?
- Is it adventure?
- Is it knowledge?
- Is it be useful to the world with your skill set?
- Is it human connection?
- Is it creative expression?
- Is it autonomy?
And why do you want those things? Which of these do you care over others?
Is what you’re doing getting to where you want?
So now that you have your values we can revisit the actions and decisions you’re making today. Does your job fulfil your values? What do you do on the weekends to compensate?
A framework to help think about your actions further is with the regret minimisation framework.
When you’re 80 years old looking back at your life. What choices are you making today would you regret?
Common pitfalls
Money
Why is it really at the top of your list? Why do you need it?
Is it so you can more easily go on adventures later? Why not just go on adventures without depending on the money step?
Borrowed dreams
Another area which is dangerous is that your ideas are heavily influenced from the ideas you hear and which are around you.
The ideas you hear about something, you’ll forget, and next time you think about that thing, you’ll accidentally regurgitate that idea you heard as your own. Thats how it works.
So truly think about the ideas you hold. Are they actually yours?
Status games
We unconsciously compete over our peers for things we don’t even want: the biggest house, the most prestigious job title, the most followers. Do you actually want these things or are you just competing?
So what are you going to do about it?
You have your values, you know what you should prioritise, are you going to keep doing what you’re currently doing?
You only have a thousand or so weeks left.
07 Jun 2025
After getting a few offers, here’s what I did and would do again if I needed to get a SWE job again.
The legs of the SWE interview chair are:
- Coding
- System design
- Behavioural
You’re going to get interviews in these areas and each company will have slight different flavours to these. My recommendation is to first do the basic prep and then focus in on companies when those interviews have been booked in. This means grepping through glassdoor for every past interview question and doing them.
On general application strategy apply to a crap ton as the more interviews you do the better you’ll get, my guess is that you’re pretty much guaranteed to fail your first one.
Coding
USE PYTHON. Some interviews cough cough stripe are impossible to do in verbose languages. Python is by far the best language to concisely explain standard interview concepts, outside of heap, but what are the chances someone asks you a heap question. lmao.
The prep is simple, just do leetcode. Here’s a nicely structured list of 150 questions. They will get easy as you do them.
System Design
First learn the basic concepts then learn the structure of how you should answer them and just choose a question and spend 30 minutes just writing down in a doc all your answers for each of the sections. As you do enough questions you’ll learn that all of the questions are pretty much the same, put a load balancer infront of a host with a db. Wow how simple. Then dump your structured answer into chat gpt and have it ask 10-20 questions on you. The llm feedback loop was extremely useful and would highly recommend.
Concepts:
How to answer a system design question:
Questions (DONT CHEAT AND READ THE LINKS, JUST READ THE CONSTRAINTS AND DO THE QUESTION ALONE FIRST):
Behavioural
Behavioural’s are just vibe checks. Theres really only a few things you need to tell who are you and why you’re the goat fit. Be interested and passionate!
Who are you:
Why you’re the goat fit:
Final questions:
Finance
Wow a surprise section, some smaller companies such as those in finance will ask more specific questions to hire for spikes. Usually this means knowing a specific language or knowing some sort of CS better, most likely operating systems. Usually they can’t actually ask you some real in-depth stuff so just reading the language docs or resources is pretty sufficient.
- What are the cache locality of data structures
- How are maps implemented under the hood
- Do some threading
- Do some naive implementations of cpp shared ptr, unique ptr, tuples
- Stack and heap memory knowledge
Closing
With this process the main thing to note is that your goal is to hold an auction for your time with as many companies as possible. You want to get as many offers at possible at the same time. To do this when you get one offer, let every other company know and that you want to accelerate the process with them because you love their company.
Negotiating for dummies:
12 Apr 2025
Measuring
There are four main branches of profiling
- Instrumentation: compiler adds extra code on each function to count it
- Debugging: profiler inserts temporary debug breakpoints at every function
- Timer based sampling: profiler tells OS to interrupt every x time and will count where these happen, less reliable
- Event sampling: profiler tells CPU to generate interrupts at certain events. Lets you see how many cache misses, branch mispredictions, etc happen. These are CPU specific!
RAM memory access is usually a major cause of perf issues, so we have memory caches to avoid this. These are the usually sizes. It takes 100s of clock cycles for a RAM access but only 5 or so for a cache hit
- L1: 64kb
- L2: 1MB
- L3: 8MB
Another common concern is context switches, OS will interrupt your process to run other stuff!
Dependency chains are another concern, microprocessors will do out of order execution, so you want to avoid long dependency chains.
And a final common concern is the using the entire CPU, microprocessors can do multiple stuff to integers and floats at the same time, SIMD!
Choosing the right algo
Before you dig into performance optimisations, first find the optimal algo!
And consider if others have already implemented already!
- Boost
- Intel math kernel library
- Intel performance primitives library
Efficiency of cpp constructs
Variable storage
Where data is stored will affect cache efficiency.
Stack storage: are the fastest because the same range of memory addresses is reused again and again, so its almost certain that this part of the memory is mirrored in the L1 data cache.
Global and static storage: separated into three parts.
- Constants
- Initialised variables
- Uninitialised variables
Main issue is that as these memory addresses arent reused, it has bad cache properties. You should just try to make all global static stuff const, as this removes a conditional check on whether if this variable is initialised or not yet.
Dynamic storage, the heap! Very slow, and heavily affected by heap fragmentation.
Variables declared inside a class. Main thing to note is that they have the same order of declaration so store variables that are used together in the same place!
Integer variables and operators
Addition, subtraction, comparison, bit operations and shift operations only take 1 clock cycle!
Multiplication will take like 11, and division is like 80 🥲.
Floating point variables and operators
Theres two different ways of doing floating point instructions.
- Use the 8 floating point x87 register stack
- Use vector registers XMM, YMM, ZMM
Float addition is like 5, multiplication is like 8 and division is like 40.
JUST AVOID CONVERSIONS! between ints and floats
Enums
Enums are just integers.
Booleans
Place conditional chains that are most true first in || for early exits!
Also bools are stored as 8 bit integers! So you can move to a char for more optimisations.
Pointers and references
Pointers and refs are equivalent n perf and honestly the perf is not that bad for local variables. Also calling out that member pointers have a bunch of possible implementations and it youre pointing to multiple inheritance pointers then thats bad.
Arrays
- the best!
- when accessing/ iterating through, you should hit adjacent bits of the array
- if its small enough to fit in l1 cache, try to make it nice power of 2
Branches and switch statements
Modern microprocessors do pipelined execution which they feed instructions into and get results. An issue of this pipeline is that it takes a while to figure out if something has gone wrong, like you’re making the wrong cake. In reality this shows up when you feed the wrong branch of a conditional into the pipeline and you gotta redo stuff taking like 20 clock cycles.
Functions
Something to note is that functions can slow down code by
- causing a microprocessor jump, taking up to 4 cycles
- code cache being less effective as you’re somewhere else now
- function parameters need to be re read
- You need to setup the stack frame
Try to
- Avoid unnecessary functions
- Use inline functions
- Avoid functions that call other functions!
- Use macros
- Use
__fastcall and __vectorcall to speed up integer parameter functions
- Add
static so they are inlined, move them to anonymous namespaces!
Function parameters
Const ref function parameters are pretty efficient, will be transferred in registers.
Function tail calls
When last return of a function is another function, compiler will just jump to second function, not a full function call, nice! Return types need to be identical tho.
Class data members
Just know that for your structs, data members have requirements of where the data member is placed in memory, is it on a alignment divisible by 8, 4, 2 or 1 bytes. This can leave holes in your classes!
Runtime type identification
Guess what similar to virtual member functions, doing type identification at runtime is also slow. Who knew.
Inheritance
Not much of a penalty with inheriting structs, but something to note is that the functions you call might be in different modules and therefore slower to call.
Bitfields
To save space you can share memory with union and specify bits you’re using with bitfields. Looks very error prone.
Templates
Something to note is you can avoid runtime virtual functions, by pushing arguments into templates!
Threads
Threads allow you to do multiple tasks at the same time, and these are distributed across your CPUs, at the cost of context switches every 30ms.
Compiler optimisations
How compilers optimise
Here’s a list of things compilers will do
- Inline functions
- Propagate constants
- Eliminate pointers, when target is known
- Eliminate subexpressions that are used frequently
- Store stuff in registers, Main callout is that if a variable has a pointer or reference to it then it can’t be stored in a register! BRUH
- Join identical branches, if both sides of a branch do the same thing, it will simplify
- Remove needless conditional jumps, by copying returns earlier
- Unroll loops
- Move code out of loops if they’re unrelated
- Vectorisation, use vector registers for handling multiple data simultaneously
- Algebraic reductions: Doesn’t work on floats very well!
Obstacles to optimisation by compiler
Theres a bunch of restrictions to compiler optimisations you should be aware of.
- Compilers can’t optimise across cpp files!
- When accessing variables through pointers, it causes issues that the compiler can’t figure out if accessed members are identical and can be reused!
- Compilers can’t know if a function is pure, so you gotta do it yourself, so it’s not called a lot of times needlessly. Or try out
__attribute__((const)) on linux!
- Virtual functions suck
- Compilers can’t do complicated algebraic reduction!
Obstacles to optimisation by CPU
The main thing to note is to avoid long dependency chains! Avoid loop carried dependency chains!
Optimisation directives
Checking compiler output
Few ways to actually do this!
- Use a compiler cli flag,
-S or /Fa, and use a disassembler on the object file
- If intel, use
/FAs or -fsource-asm but will rpevent some optimisations
Memory optimisations
Cache code and data
Cache organisation
Caches are organised into lines and sets. This is the n way set associative cache. So on a memory address modulo will choose which set it uses. The key thing to be aware of is how far a memory address needs to be away for it to be a cache hit or not. AKA the critical stride `num sets x line size = total cache size / number of ways
Functions that are used together should be stored together
Variables that are used together should be stored together
Alignment of data
As you already know variables are auto aligned and this can cause needless holes in your structs. So you should reorder them.
You can also align large objects by the cache line size alignas(64) int arr[1024]. So your nice array will start at a cache line.
Data structures and container classes
- If the maximum number of elements is known at compile time or a decent upper limit can be set, use a fixed size array.
- Avoid additional allocations by reserving your vectors!
- FIFO: queue
- LIFO: array with stack pointer
- need ordering: sorted list, bin tree
Explicit cache control
Modern processors already prefetch, so you _mm_prefetch isnt really necessary.
You can also do __mm_stream_pi to do writes without triggering a cache refresh.
Multithreading
Theres three ways of doing things in parallel
- Use multiple CPUs
- Use multi core CPUs
- Use out of order execution
- Use vector operations
Out of order execution
CPUs can actually handle more than a hundred pending operations at once, can be useful to split a loop into two and store intermediate results in order to break a long dependency chain.
Vectorising
SIMD, single instruction multiple data operations can make stuff much faster! The vector register size depends on the instruction set you’re using.
When working you can do the following to do simd with pointers better
#pragma vector aligned- declare functions inline
Do the following for better auto vectorisation
- When accessing through pointers, tell the compiler explicitly that the pointers do not alias, with
__restrict or __restrict__ keyword.
- Use less restrictive floating point operations.
-02 -fno-trapping-math -fno-math-errno -fno-signed-zeros -ffast-math
-
AVX instruction set and YMM registers
AVX512 instruction set and ZMM registers
Automatic vectorisation
Using intrinsic functions
Using vector classes
Mathematical functions for vectors
Aligning dynamically allocated memory
Aligning RGB video or 3 dimensional vectors
Conclusion
Instruction sets
Specific optimisation topics
Using lookup tables
Bounds checking
bitwise operations for checking multiple values at once
Integer multiplication
Integer division
Floating point division
Do not mix float and double
Conversions between floats and ints
Integer operations on floats
Math functions
Static vs dynamic libraries
Position independent code
Systems programming
Testing speed
Pitfalls of unit testing
Worst case testing
Embedded systems
Compiler options
Appendix